
Neurosymbolic AI for Planning
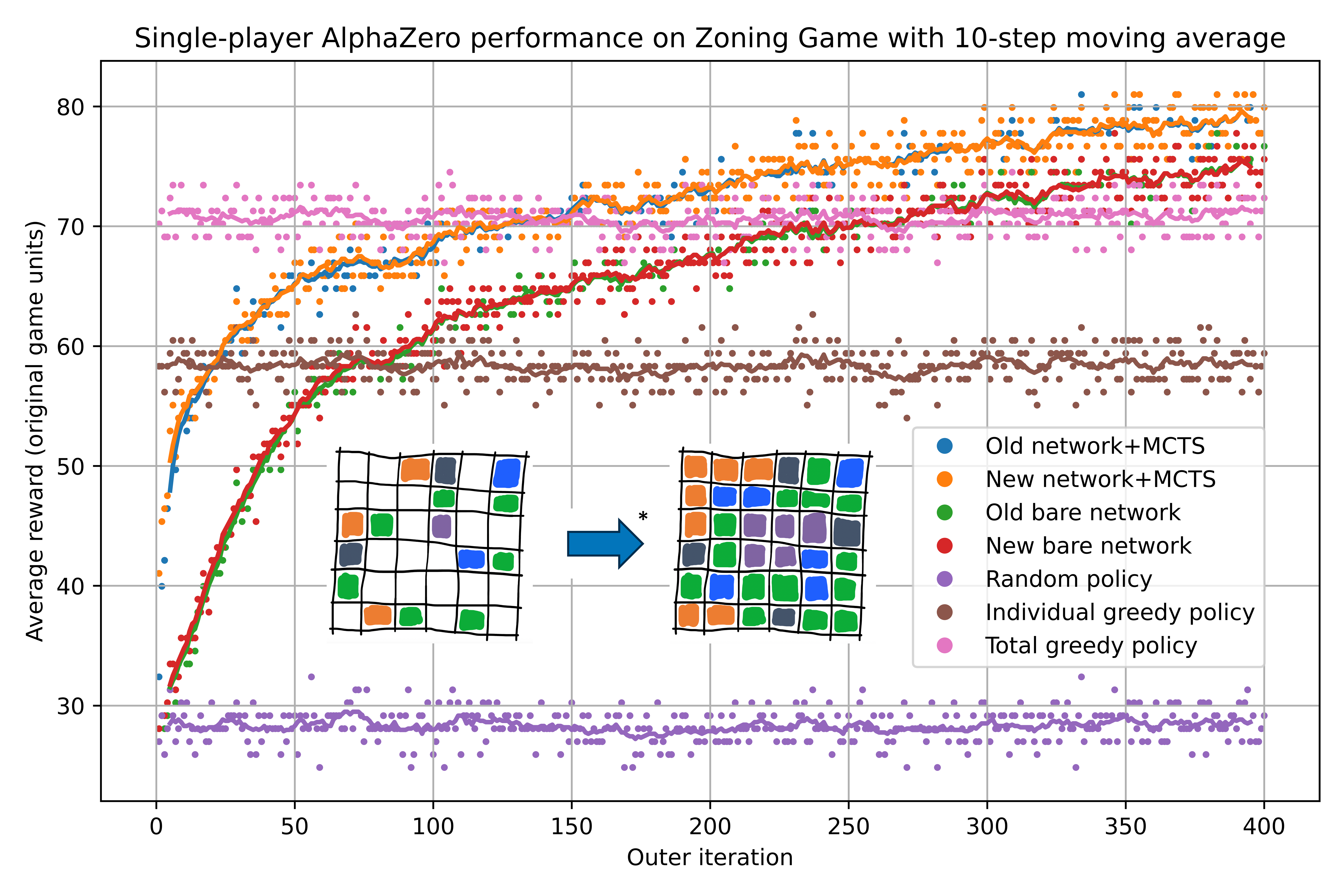
The above draft illustration (not finalized, should not be cited, etc.) depicts our single-player reimplementation of AlphaZero learning to play our novel ‘Zoning Game.’ At each outer iteration of training, the agent is tested on randomly-initialized game configurations it did not encounter in training; shown is its average performance. Blue and orange are the previous and current full versions of the agents, which rely on both a neural network and Monte Carlo tree search (MCTS); green and red are previous and current versions playing with just the raw neural network predictions. Purple is a hand-coded ‘control’ policy that picks a random move every turn, brown is a policy that maximizes the immediate score of the tile being placed at each step, and pink is a policy that maximizes the immediate total grid score at each step. The fact that AlphaZero’s performance surpasses all these benchmarks means that in a sense it is learning to “think ahead.” Inset is an example initial and final game state.
*Quick links: open the above image in a new tab, very in-progress GitHub repo.
Some time after joining the National Renewable Energy Lab, I attended a fascinating talk by veteran researcher Peter Graf on neurosymbolic AI. This approach to artificial intelligence combines modern deep learning methods based on neural networks with more traditional techniques that rely on performing interpretable, logical operations on pieces of information that directly represent the domain. A prominent example of an algorithm that could be called neurosymbolic is Google DeepMind’s AlphaZero, which combines neural policy and value networks with Monte Carlo tree search (MCTS), a classic approach that explicitly represents a tree of possible game states. AlphaZero achieved record-breaking performance in games like Go and chess and has subsequently been applied to more practical problems, including finding faster algorithms for matrix multiplication (“AlphaTensor”) and sorting lists of numbers (“AlphaDev”). I reached out to Peter to discuss a possible collaboration and he was receptive; ultimately, we set out to study how neurosymbolic AI might be applied to real-world planning problems, such as those encountered when expanding the electrical power grid.
Grid expansion planning is a key bottleneck in both the transition to renewable energy and the serving of new loads such as AI datacenters. However, there are reasons to be skeptical that a black-box machine learning approach that directly outputs decisions would be a good match for this problem. Given the high stakes nature of grid planning, it is important that AI-derived solutions be explainable, and in certain related areas such as power market design, a written policy that explains how the system works is imperative so that market participants can understand how to contribute. Inspired by AlphaTensor, AlphaDev, and other work applying AlphaZero-like algorithms to the problem of symbolic regression, we wondered if, given a context-free grammar (CFG) describing a space of possible sets of rules for how a system could work (we call these ‘programs’), we could train AlphaZero to select the best program on a given metric.
To make this problem concrete without needing to deal with the full complexity of a real-world system, I created the Zoning Game, very roughly inspired by city zoning. The game is played with a square grid that comes partially pre-filled with tiles representing zone types: residential, industrial, commercial, etc. (see above), and a queue of tiles to add to the grid. Each turn, the player selects where in the grid to place the next tile in the queue. Each zone type has preferences — residential would prefer not to be near industrial, industrial would prefer to be near the horizontal and vertical centerlines of the board (suppose there are railroads there), etc., and the object of the game is to maximize the extent to which everyone’s preferences are satisfied at the end of the game. Given known preferences, it is straightforward to design hand-coded ‘greedy’ agents that maximize some immediate preference satisfaction, but planning ahead to maximize the final score is harder.
My next step was to write my own single-player AlphaZero implementation, both to deepen my own understanding of the algorithm and to provide a well-designed, modular algorithm base to build upon as we experimented with various games and network architectures. The figure above depicts this AlphaZero agent learning to play the Zoning Game better than those greedy agents, demonstrating that it is doing something equivalent to planning ahead.
Now that we have all this infrastructure in place, it’s time to get back to the matter of program generation. We have a context-free grammar that can express rules like “industrial may not be placed next to residential” or “downtown must be placed within 2 tiles of the center of the board,” and we have proof that the greedy agents’ performance can be improved by constraining it with certain rules, so our next step is getting AlphaZero to produce the best set of rules, measured by how much it improves a greedy agent. We’re hoping for results on this soon!